先日、面白いゼミを参加しました。
自然言語処理方面のことを紹介していました。
モデルの発展は面白いので、少し紹介させていただきたいです。
1:自然言語処理とは何?
自然言語処理(NLP, nature language process)には、3つテーマがあります:
- 感情分析(sentiment analysis)
- 問答(question answering)
- 翻訳(mashine translating)
この中で、翻訳は一番典型的な自然言語処理問題です。
でも、コアの問答は、自然言語を理解するです。この問題を解決するため、色々なモデルを提出しました。
2:古典的なモデル(向量空間モデル、vector space model)
このモデルは、deep learningまたはmaching learning前にとても流行したモデルです。
一番有名のは、TF-IDFモデルです。
TF-IDF(term frequency–inverse document frequency)、これは統計学的な方法です。
簡単に言うと、ある文章の集まりの中に、ひとつの単語が少数の文章内しか出てこないなら、この単語はこの文章の集まりのキーワードです。
この原理は、シャノンの情報定理を利用して解析できます:不確定なもののほうがより情報の価値が高いです。
情報の価値が高い単語はキーワードです。
このモデルはとても素晴らしいので、色々な方面で利用されています。
グーグルも最初はこのモデルの変種を利用してsearching engineを作りました。
今でも、文章の主旨をまとめるときに利用しています。
3:現代的なモデル
機械学習、特にdeep learningを発展させて、色々な強力なモデルを出てきます。
RNN(Recurrent Neural Networks)
deep learningを利用して、自然言語処理問題を解決する典型なモデルです。
普通、ニューラルネットワークの出力は出力層に出力します。
でもRNNは、ニューラルネットワークの出力はもう一度ニューラルネットワークに入力します。
このせいで、ニューラルネットワークはものの前後関係を理解できます。
自然言語にとって前後関係はとても重要だから、RNNは自然言語を処理するのは適しています。
ちなみに、RNNは、時間関係の問題も処理できます。
seq2seq
これは翻訳問題に対して一番新しいモデルです。
以前、英語とアラビア語の翻訳は、最大は87%の正確率ですが、このモデルを利用したら、すぐ92%以上になりました。
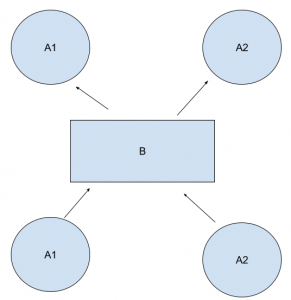
簡単に言うと、A1とA2が違う言語とします。
Bはモデルです。
A1にBを入力して、A2を出力しました。
A2はBを入力して、A1を出力しました。
これは実際の翻訳過程ですね。
もしsample量が多いなら、正確率は高くなります。
英語とアラビア語の翻訳がそんなに正確率が高い原因は、古代から現代まで、いっぱい翻訳資料があるからです。
sample量が多くないのせいで、英語と日本語の正確率はあまり正しくありません。
今回の記事はここまでです。
ご覧頂きありがとうございます!
中国広東省出身、京都オフィス勤務のエンジニア。機械学習に興味がある。京都大学留学生として来日して以来、京都の住みやすさが気に入っている。